bulk_reshuffle #
Description #
The bulk_reshuffle filter is used to parse batch requests of Elasticsearch based on document, sort out documents as needed, and archive and store them in queues. After documents are stored, the filter can rapidly return service requests, thereby decoupling front-end writing from back-end Elasticsearch clusters. The bulk_reshuffle filter needs to be used in combination with offline pipeline consumption tasks.
When passing through queues generated by the bulk_reshuffle filter, metadata carries "type": "bulk_reshuffle" and Elasticsearch cluster information such as "elasticsearch": "dev", by default. You can call APIs on the gateway to check metadata defined in queues. See the following example.
curl http://localhost:2900/queue/stats
{
"queue": {
"disk": {
"async_bulk-cluster##dev": {
"depth": 0,
"metadata": {
"source": "dynamic",
"id": "c71f7pqi4h92kki4qrvg",
"name": "async_bulk-cluster##dev",
"label": {
"elasticsearch": "dev",
"level": "cluster",
"type": "bulk_reshuffle"
}
}
}
}
}
}
Node-Level Asynchronous Submission #
INFINI Gateway is capable of locally calculating the target storage location of a back-end Elasticsearch cluster corresponding to each index document so as to precisely locate requests. A batch of bulk requests may contain the data of multiple back-end nodes. The bulk_reshuffle filter is used to shuffle normal bulk requests and reassemble them based on target nodes or shards. The purpose is to prevent Elasticsearch nodes from distributing received requests, so as to reduce the traffic and load between Elasticsearch clusters. The filter also prevents a single node from becoming a bottleneck and ensures balanced processing of all data nodes, thereby improving the overall index throughput of clusters.
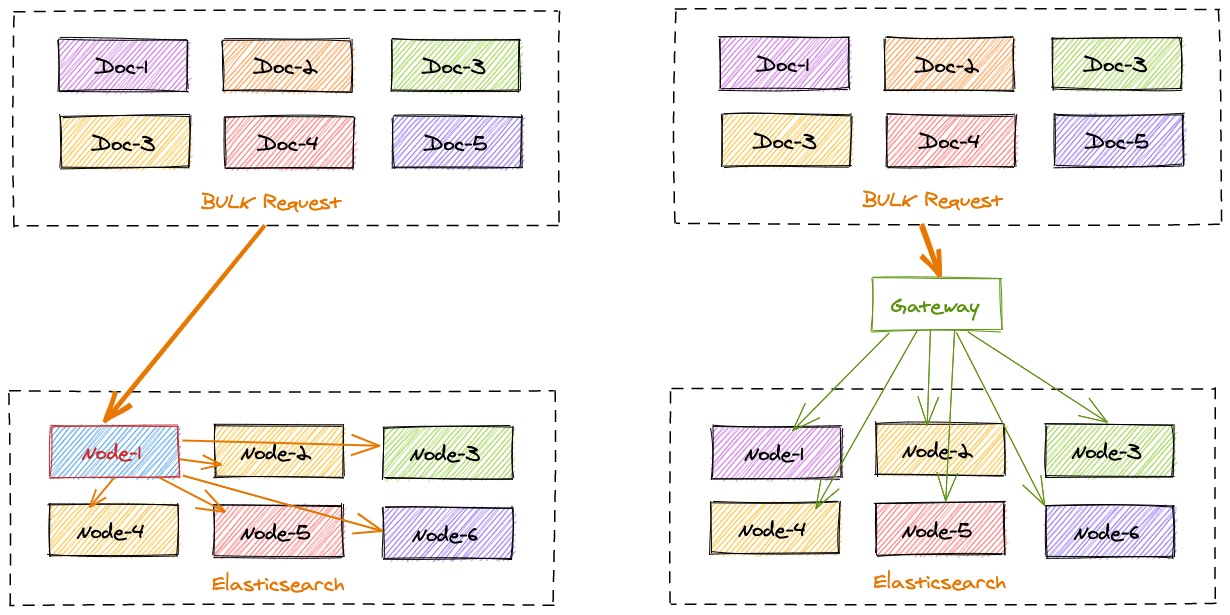
Defining a Flow #
A simple example is as follows:
flow:
- name: online_indexing_merge
filter:
- bulk_reshuffle:
elasticsearch: prod
level: node #cluster,node,shard,partition
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
elastic:
enabled: true
remote_configs: false
health_check:
enabled: true
interval: 30s
availability_check:
enabled: true
interval: 60s
metadata_refresh:
enabled: true
interval: 30s
cluster_settings_check:
enabled: false
interval: 20s
The above configuration indicates that bulk requests will be split and reassembled based on the target nodes corresponding to index documents. Data is sent to local disk queues first and then consumed and submitted through separate tasks to the target Elasticsearch nodes.
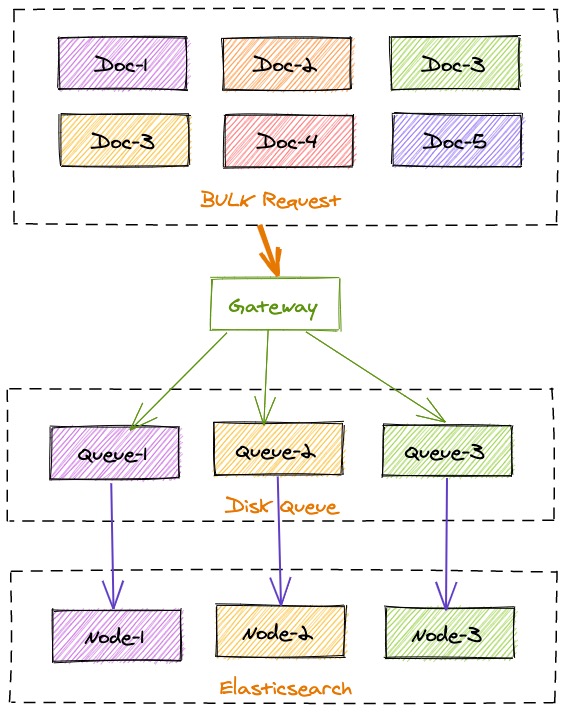
The benefit of this filter is that a failure occurring on the back-end Elasticsearch cluster will not affect indexing operations because requests are stored in disk queues of the gateway and the front-end indexing is decoupled from back-end clusters. Therefore, when the back-end Elasticsearch cluster encounters a failure, restarts, or initiates version upgrade, normal index operations will not be affected.
Configuring a Consumption Pipeline #
After the gateway sends requests to the disk, a consumption queue pipeline needs to be configured as follows to submit data:
pipeline:
- name: bulk_request_ingest
auto_start: true
processor:
- bulk_indexing:
queues:
type: bulk_reshuffle
level: node
One pipeline task named bulk_request_ingest is used and the filter conditions for queues of to-be-subscribed targets are type: bulk_reshuffle and level: node. You can also set the batch size for bulk submission.
In this way, node-level requests received by INFINI Gateway will be automatically sent to the corresponding Elasticsearch node.
Shard-Level Asynchronous Submission #
Shard-level asynchronous submission is suitable for scenarios in which the data amount of a single index is large and needs to be processed independently. An index is split into shards and then bulk requests are submitted in the form of shards, which further improves the processing efficiency of back-end Elasticsearch nodes.
The configuration is as follows:
Defining a Flow #
flow:
- name: online_indexing_merge
filter:
- bulk_reshuffle:
elasticsearch: prod
level: shard
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
Set the assembly and disassembly level to the shard type.
Defining a Pipeline #
pipeline:
- name: bulk_request_ingest
auto_start: true
processor:
- bulk_indexing:
queues:
type: bulk_reshuffle
level: shard
Compared with the preceding node-level configuration, the level parameter is modified to listen to shard-type disk queues. If there are many indexes, excess local disk queues will cause extra overhead. You are advised to enable this mode only for specific indexes whose throughput needs to be optimized.
Parameter Description #
| Name | Type | Description |
|---|---|---|
| elasticsearch | string | Name of an Elasticsearch cluster instance. |
| level | string | Shuffle level of a request, that is, cluster level. The default value is cluster. It can be set to cluster, node, index, or shard. |
| queue_name_prefix | string | The prefix of default queue,The default value is async_bulk |
| partition_size | int | Maximum partition size. Partitioning is performed by document _id on the basis of level. |
| fix_null_id | bool | Whether to automatically generate a random UUID if no document ID is specified in the bulk index request document. It is applicable to data of the log type. The default value is true. |
| continue_metadata_missing | bool | If the node or shard information required by the context does not exist, whether to continue or skip process,default false |
| continue_after_reshuffle | bool | Whether to continue with the process after finished the reshuffle process,default false |
| index_stats_analysis | bool | Whether to record index name statistics to request logs. The default value is true. |
| action_stats_analysis | bool | Whether to record bulk request statistics to request logs. The default value is true. |
| shards | array | Index shards that can be processed. The value is a character array, for example, "0". All shards are processed by default, and you can set specific shards to be processed. |
| tag_on_success | array | Specified tag to be attached to request context after all bulk requests are processed. |