How an Insurance Group Improved the Indexing Speed by 200x Times #
Challenges #
A large insurance group places common database fields in Elasticsearch to improve the query performance for its policy query service. The cluster is deployed on 14 physical machines, with 4 Elasticsearch instances deployed on each physical machine. The whole cluster has more than 9 billion pieces of data. The storage size of index primary shards is close to 5 TB, and about 600 million pieces of incremental data are updated every day. Due to the service particularity, all the service data across the country is stored in one index, resulting in up to 210 shards in the single index. The bulk rebuilding task is executed in parallel by Spark. The average write speed is about 2,000–3,000 pieces per second. One incremental rebuilding operation may take 2–3 days. Service data updating causes a large delay and the lengthy rebuilding also affects service access during normal time periods. The technical team had tried hard to optimize Elasticsearch and also the Spark write end for several rounds, but did not get any progress in the indexing speed improvement.
Scenario #
The analysis shows that the cluster performance is good. However, after write requests in a single batch are received by Elasticsearch, they need to be encapsulated and forwarded according to the node where the primary shard is located. There are too many service index shards and each data node eventually gets a very small number of request documents. One bulk write request of the client is divided into hundreds of small bulk requests. According to the short board theory of the barrel, the processing speed of the slowest node slows down the whole bulk write operation. INFINI Gateway knows where a document should go to.
INFINI Gateway is capable of splitting and merging requests in advance. It splits and merges requests in advance, sends the requests to local queues based on the target node, and then writes the requests to the target Elasticsearch cluster through the queue consumption program to convert random bulk requests into sequential requests that are precisely delivered. See the figure below.
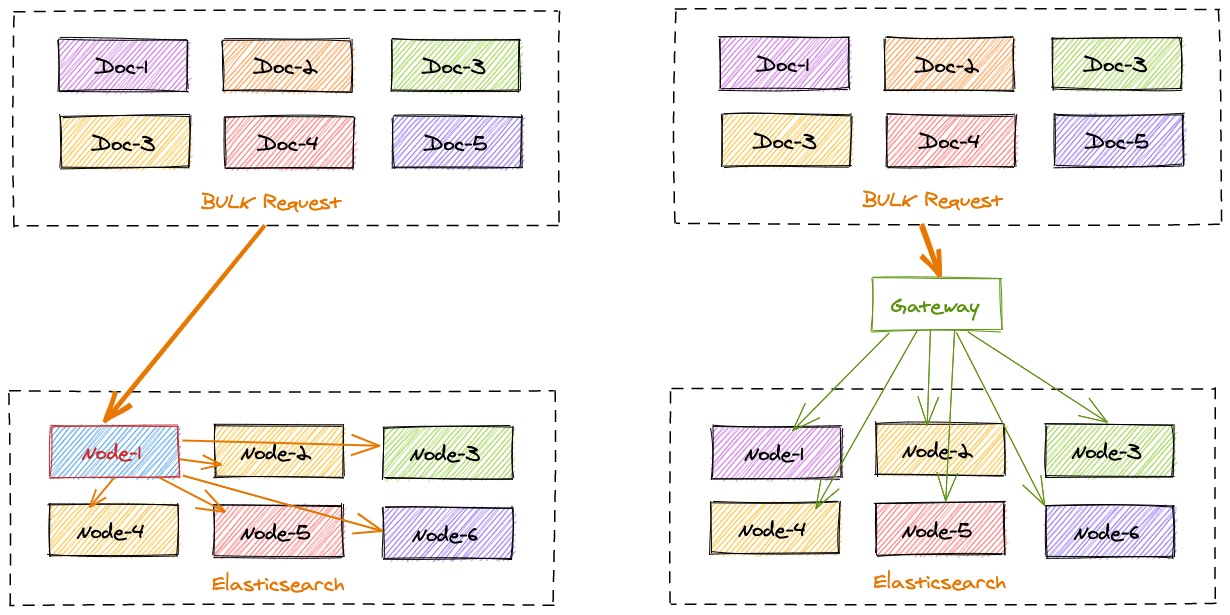
After receiving a request from Spark, INFINI Gateway first stores the request on the local disk to prevent data loss. Meanwhile, INFINI Gateway can locally calculate the routing information of each document and the target data nodes. The new data writing architecture is shown in the figure below.
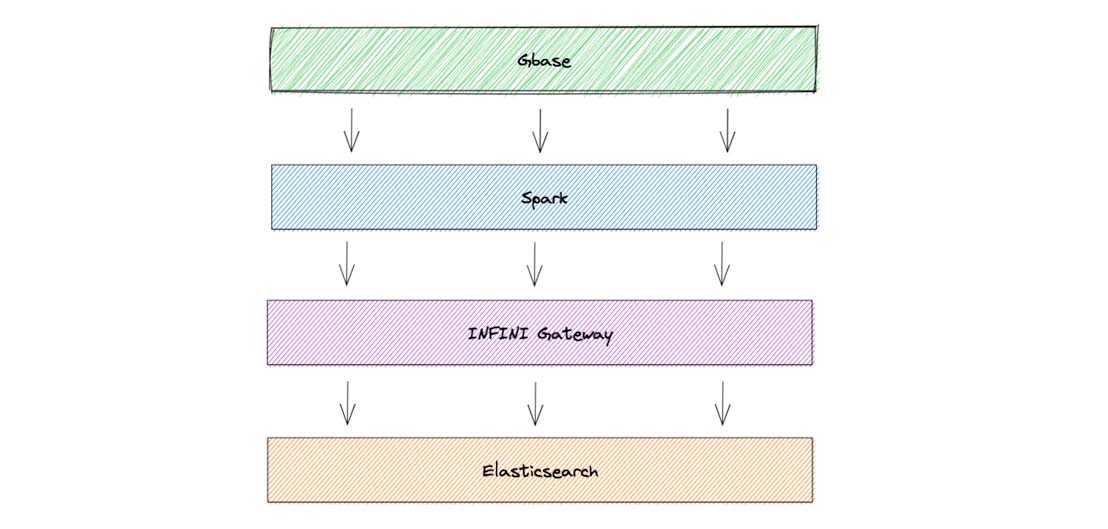
After INFINI Gateway is used to receive write requests from Spark, the write throughput of the entire cluster is significantly improved. Spark accomplishes the data writing task in less than 15 minutes, and it takes only 20 minutes for the gateway to receive requests and write them into Elasticsearch. The CPU resources of the server are fully utilized and all the CPU resources of each node are used.
User Benefits #
The Indexing Speed Is Improved by 20,000%
After INFINI Gateway is used as the intermediate acceleration layer, the index rebuilding cycle of the group’s policy service is reduced from 2–3 days to about 20 minutes, the 600 million pieces of daily incremental data can also be rebuilt very quickly, and the peak index write QPS can exceed 300,000. In a word, INFINI Gateway greatly shortens the index rebuilding cycle, reduces data latency, enhances the consistency of online data, and ensures the normal use of the query service.