How to monitor Elasticsearch cluster node disk usage #
Introduction #
When the system disk usage is too high, data cannot be written into the Elasticsearch cluster, which is likely to result in data loss. Therefore, monitor the Elasticsearch cluster. Node disk usage is necessary. This article will show you how to monitor your Elasticsearch cluster using INFINI Console alerts Node disk usage.
Prepare #
- Download and install the latest version of INFINI Console
- Register Elasticsearch cluster using INFINI Console
Create alerting rule #
Open INFINI Console in the browser, click on the left menu “Alerting” > Rules to enter the alerting management page, and then click
New button to enter the Create Alerting Rule page. Follow these steps to create an alerting rule:
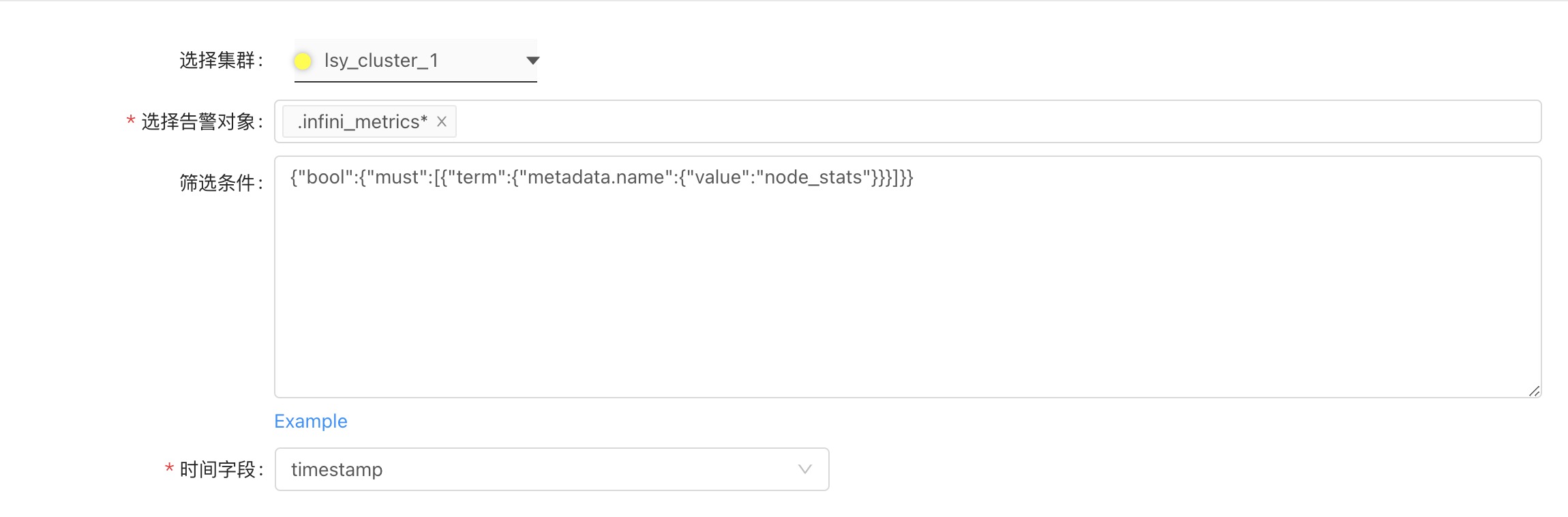
- Select the cluster (here you need to select the Elasticsearch cluster where the INFINI Console stores data, that is, the Elasticsearch cluster configured in the configuration file
console.yml, if it is not registered to the INFINI Console, please register first) - Input the alerting object
.infini_metrics*(select the index under the Elasticsearch cluster, or enter the index pattern, because the monitoring data collected by the INFINI Console is stored in the index .infini_metrics) - Input filter criteria (Elasticsearch query DSL)
Here we need to filter the monitoring metrics category to
node_stats, the DSL is as follows:
{
"bool": {
"must": [
{
"term": {
"metadata.name": {
"value": "node_stats"
}
}
}
]
}
}
- Select time field
timestampand statistical period fordate histogramaggregation
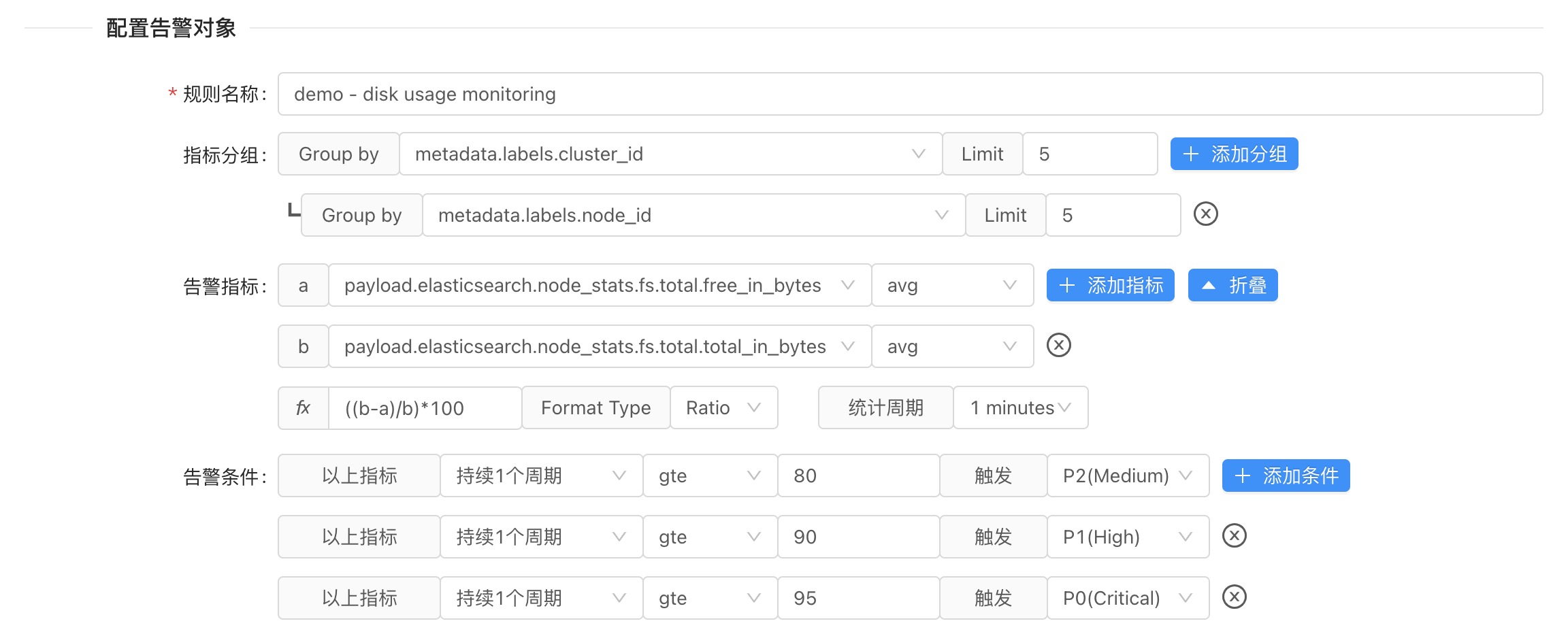
- Input the rule name
- Group settings (optional, multiple can be configured), set when statistical metrics need to be grouped, because all registered to INFINI Console
The Elasticsearch cluster monitoring metrics are stored in the index
.infini_metrics, so you need to group according to the cluster ID first, and then group according to the node ID, Here we choosemetadata.labels.cluster_idandmetadata.labels.node_id - Configure the alerting metrics, select the aggregation field
payload.elasticsearch.node_stats.fs.total.free_in_bytes, and the statistics methodavg. Then add another alerting metrics, select the aggregation fieldpayload.elasticsearch.node_stats.fs.total.total_in_bytes, and the statistical methodavg. - Configure the metrics formula (when more than one alerting metrics is configured, you need to set a formula to calculate the target metrics), where the formula fx is configured as
((b-a)/b)*100, which means to use thetotal Disk spacesubtractremaining disk spaceto getdisk used space, Then dividedisk used spacebytotal disk spaceand multiply by 100 to getdisk usage - Configure the alerting conditions, here configure three alerting conditions, configure the
P2(Medium)alerting when the disk usage is greater than 80 forpersisting for one period; Configure thecontinue for one periodwhen the disk usage is greater than 90, trigger theP1(High)alerting; Configurepersisting for a periodwhen the disk usage rate is greater than 95, trigger theP0(Critical)alerting; - Set the execution period, here is configured to execute a check every minute
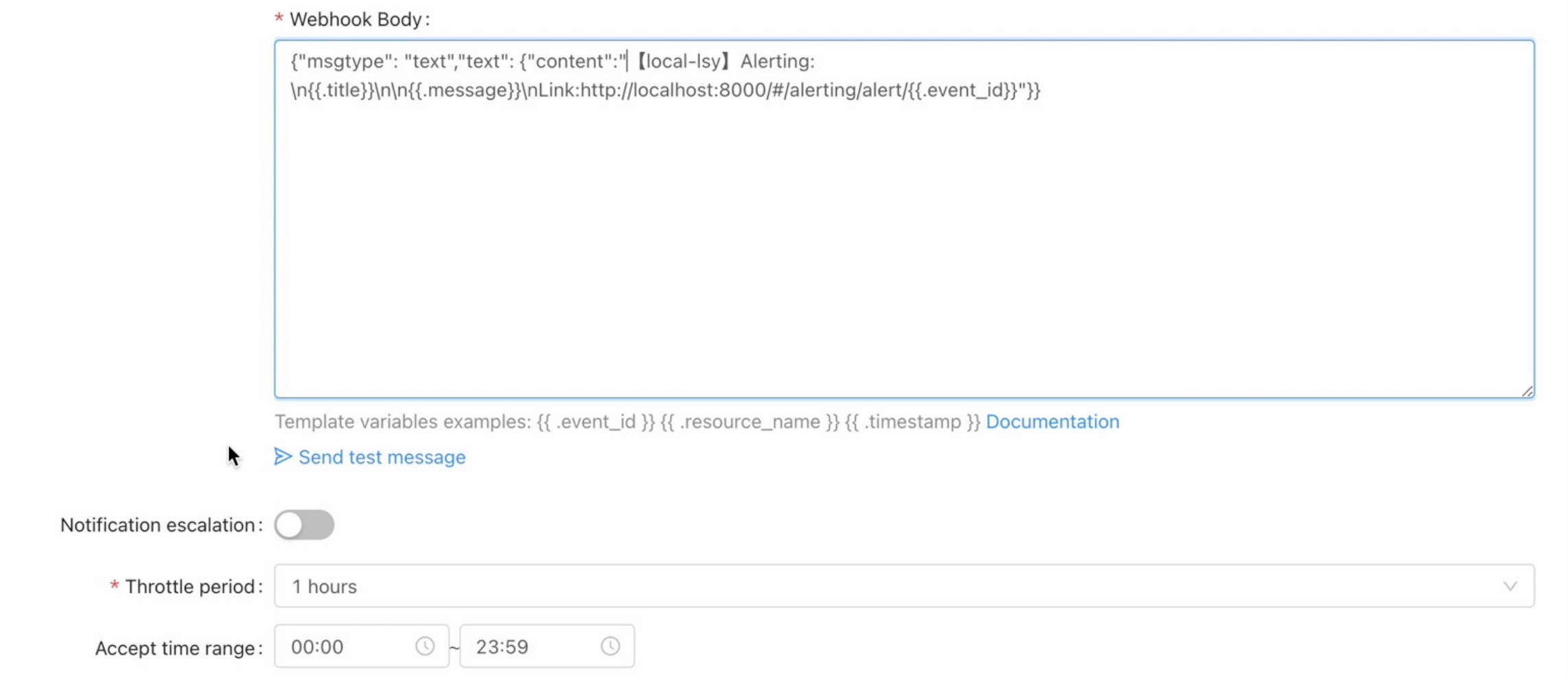
- Set the event title, the event title is a template, you can use template variables, template syntax and template variable usage reference here
- Set the event content, the event content is a template, you can use template variables, template syntax and template variable usage reference here
Priority:{{.priority}}
Timestamp:{{.timestamp | datetime}}
RuleID:{{.rule_id}}
EventID:{{.event_id}}
{{range.results}}
ClusterID: {{index.group_values 0}};
NodeID: {{index.group_values 1}};
Disk Usage:{{.result_value | to_fixed 2}}%;
Free Storage: {{.relation_values.a | format_bytes 2}};
{{end}}

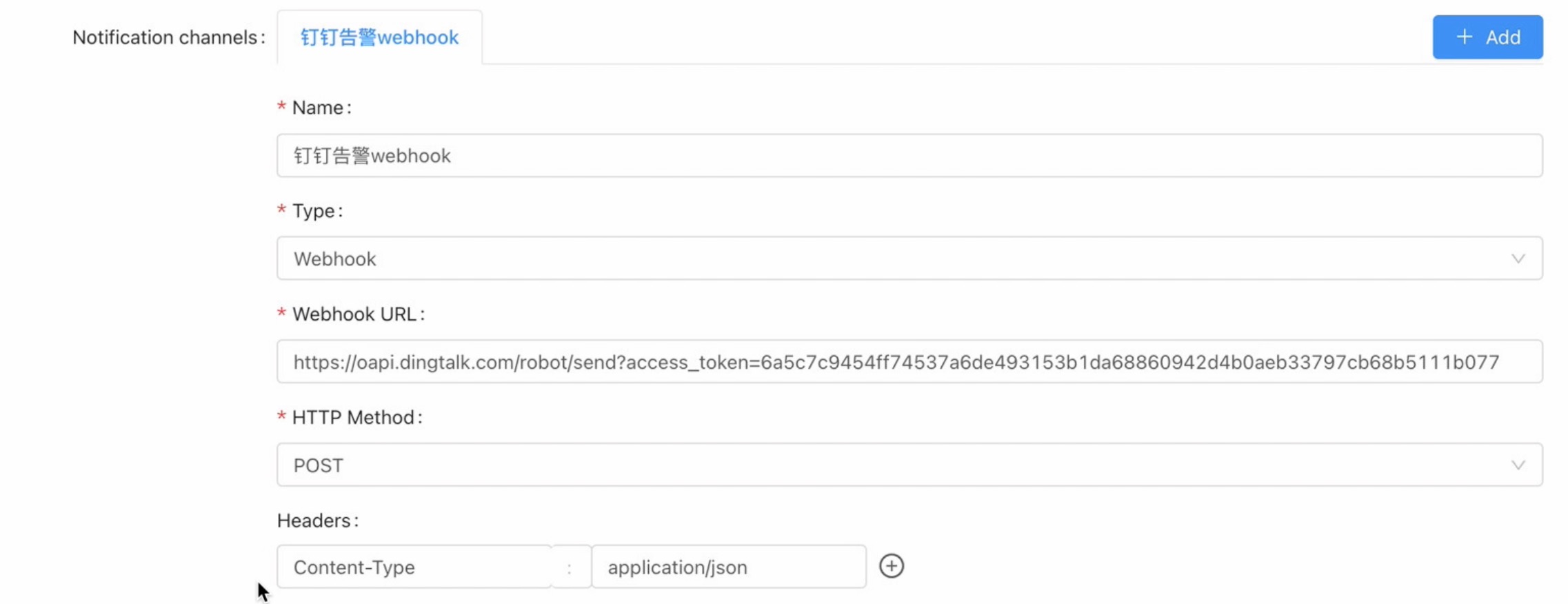
- Turn on the configure alerting channel switch, and select
addin the upper right corner to quickly select an alerting channel template to fill. For how to create an alerting channel template, please refer to here - Set the silence period to 1 hour, that is, after the alerting rule is triggered, the notification message will only be sent once within an hour
- Set the receiving period, the default is 00:00-23:59, that is, you can receive notification messages throughout the day
After the settings are complete, click the Save button to submit.
Receive alert notification message #
Wait for a while, and receive the DingTalk alerting message notification as follows:
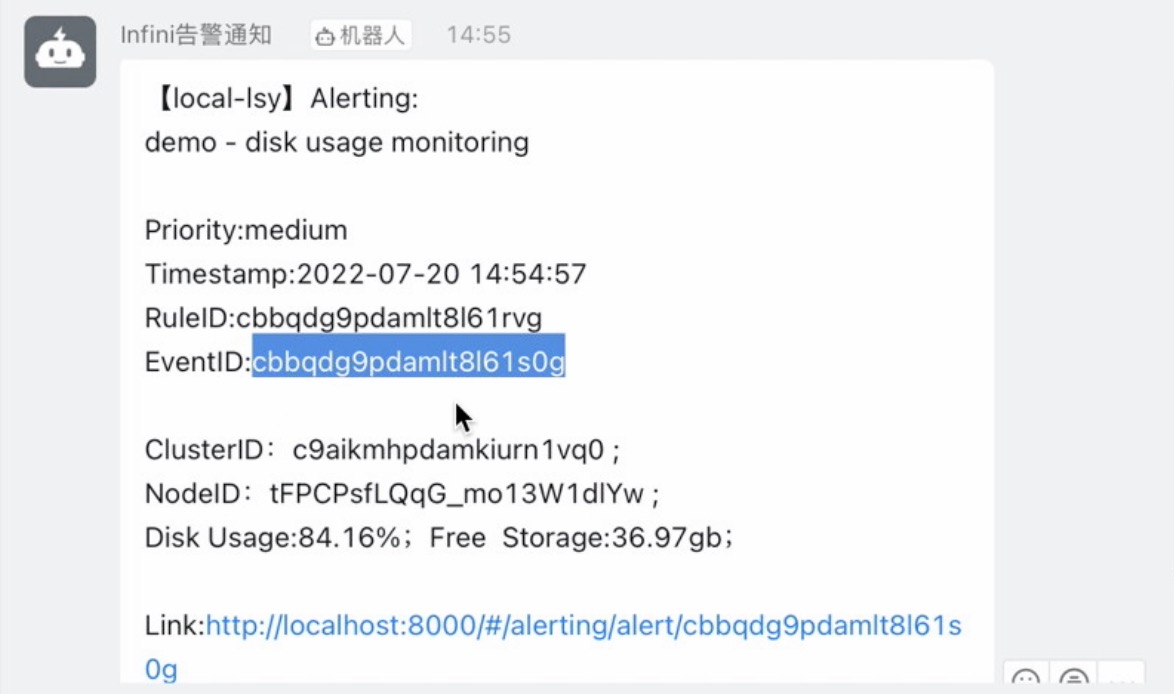
You can see that the alert notification message displays the Elasticsearch cluster ID, node ID, and remaining disk space with high disk usage.
View the alerting message center #
In addition to receiving external notification messages, the INFINI Console Alert Message Center also generates an alert message. Click menu Alerting > Alerting Center to enter
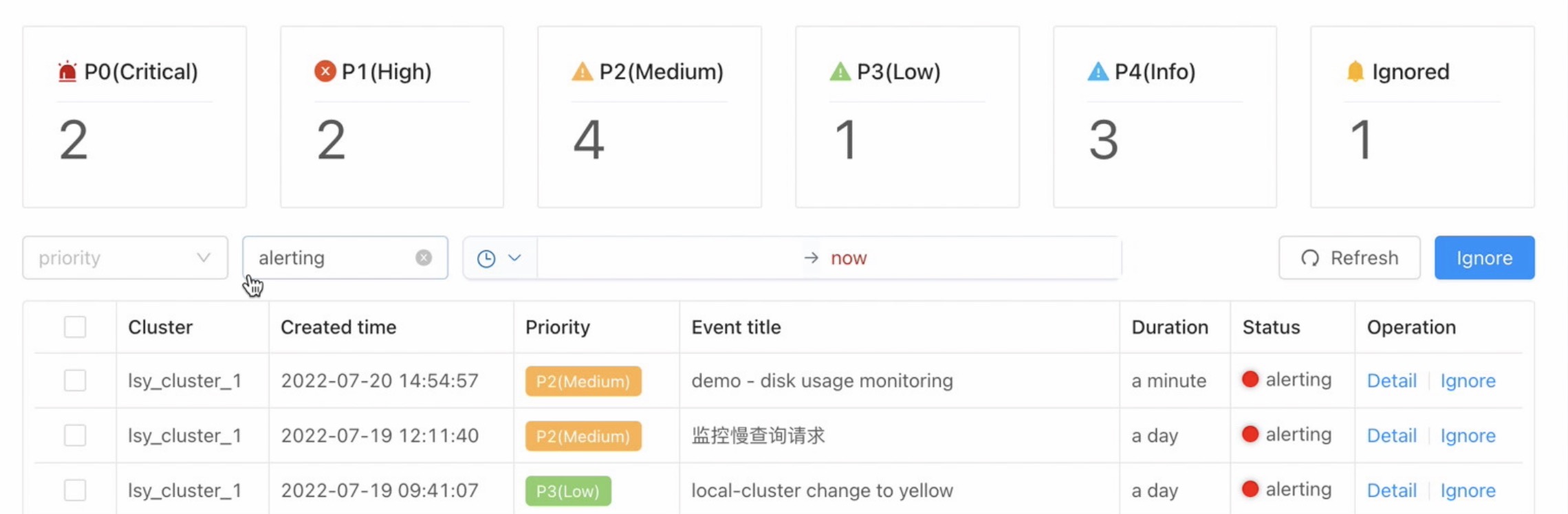
Summary #
By using the INFINI Console alerting function, you can easily monitor the disk usage of Elasticsearch cluster nodes. After configuring alerting rule, Once the disk usage of any Elasticsearch node exceeds the set threshold, an alert will be triggered and an alert message will be sent.