搜索请求文本向量化 #
Easysearch 使用搜索管道的 semantic_query_enricher 处理器,协助 semantic query,将文本转为向量。
搜索管道 #
您可以使用搜索管道构建新的或重用现有的结果重排器、查询重写器以及其他对查询或结果进行操作的组件。搜索管道使您能够更轻松地在 Easysearch 中处理搜索查询和搜索结果。 将部分应用程序功能迁移到 Easysearch 搜索管道中可以降低应用程序的整体复杂性。作为搜索管道的一部分,您可以指定执行模块化任务的处理器列表。 然后,您可以轻松添加或重新排序这些处理器,以自定义应用程序的搜索结果。
以下是与搜索管道相关的术语列表:
- 搜索请求处理器(Search request processor):拦截搜索请求(即查询及随请求传入的元数据),对其执行某种操作,然后返回处理后的搜索请求。
- 搜索响应处理器(Search response processor):拦截搜索响应及其对应的搜索请求(即查询、结果及随请求传入的元数据),对其执行某种操作,然后返回处理后的搜索响应。
- 处理器(Processor):泛指搜索请求处理器或搜索响应处理器。
- 搜索管道(Search pipeline):在 Easysearch 中集成的一个有序处理器列表。该管道会拦截查询,先对查询进行处理,再将其发往 Easysearch;随后拦截返回的结果,对结果进行处理,最后将结果返回给调用方,如下图所示。
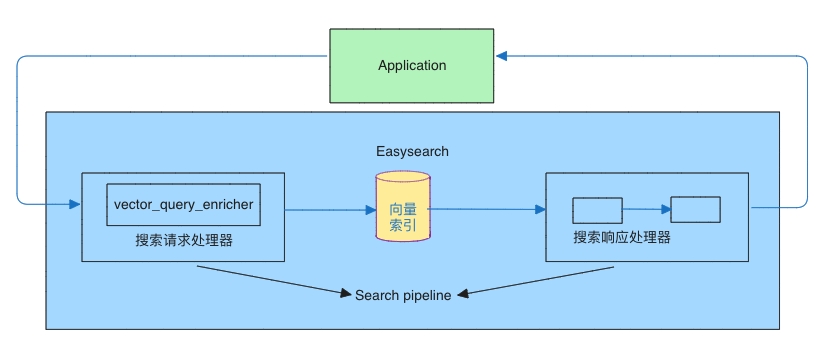
上图中的 semantic_query_enricher 是一个专门为向量查询补充 Embedding 请求所需配置的处理器,使用户无需在每个查询中重复指定模型 ID、API 密钥等参数。
先决条件 #
服务兼容性 需满足以下任一条件:
- 支持与 OpenAI API 兼容的 embedding 接口
- 支持 Ollama embedding 接口
插件要求 必须安装 Easysearch 的以下插件:
knn ai数据准备 需预先完成:
- 创建向量索引
- 写入向量数据
- 参考 写入数据文本向量化
创建或更新 semantic_query_enricher 处理器 #
PUT /_search/pipeline/default_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher" : {
"tag": "tag1",
"description": "Sets the default embedding model",
"url": "https://api.openai.com/v1/embeddings",
"vendor": "openai",
"api_key": "<api_key>",
"default_model_id": "text-embedding-3-small",
"vector_field_model_id": {
"text_vector": "text-embedding-3-small"
}
}
}
]
}
请求体字段: #
下表列出了用于创建或更新管道的请求体字段。
| 参数 | 是否必填 | 类型 | 说明 |
|---|---|---|---|
request_processors | 必填 | 数组 | 处理器列表,按顺序执行。示例中为 semantic_query_enricher。 |
tag | 可选 | 字符串 | 处理器标签,用于调试或日志(如 "tag1")。 |
description | 可选 | 字符串 | 管道描述,用于说明用途(如 “Sets the default model ID at index and field levels”)。 |
url | 必填 | 字符串 | Embedding API 的完整 URL(如 https://poloai.top/v1/embeddings)。 |
vendor | 必填 | 字符串 | 服务提供商标识,如 "openai"。 |
api_key | 必填 | 字符串 | API 密钥,需替换为实际值(如 "sk-xxx")。 |
default_model_id | 可选 | 字符串 | 全局默认模型 ID,当字段未在 vector_field_model_id 中配置时使用(如 text-embedding-3-small)。 |
vector_field_model_id | 可选 | 对象 | 字段级模型映射,如 { "text_vector": "text-embedding-3-small" },优先级高于 default_model_id。 |
查看搜索管道 #
要查看刚创建的所有搜索管道,请使用以下请求:
GET _search/pipeline/default_model_pipeline
响应包含您在上一节中设置的管道:
{
"default_model_pipeline": {
"request_processors": [
{
"semantic_query_enricher": {
"api_key": "*************************************************vE",
"vendor": "openai",
"description": "Sets the default embedding model",
"tag": "tag1",
"vector_field_model_id": {
"text_vector": "text-embedding-3-small"
},
"default_model_id": "text-embedding-3-small",
"url": "https://api.openai.com/v1/embeddings"
}
}
]
}
}
api_key 会被遮掩,防止泄露
设置默认搜索管道 #
可以将 default_model_pipeline 设置为索引默认的搜索管道,避免每次请求提供搜索管道参数。
PUT /my-index/_settings
{
"index.search.default_pipeline" : "default_model_pipeline"
}
使用 semantic query 进行搜索 #
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "这是另一个示例文本,这次使用 POST。",
"candidates": 100,
"query_strategy": "LSH_COSINE"
}
}
}
}
Vector Query 参数说明 #
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
semantic | string | 是 | - | 查询类型标识,表示这是一个将文本自动转成向量的查询。 |
text_vector | string | 是 | - | 目标向量字段名(需在 mapping 中定义为 dense_vector 类型) |
query_text | string | 是 | - | 需要编码为向量的文本内容 |
candidates | integer | 否 | 100 | 召回阶段每个 segment 考虑的候选文档数量,值越大召回率越高,性能开销越大 |
query_strategy | enum | 否 | LSH_COSINE | 近似最近邻算法策略,可选值: |
- LSH_COSINE:局部敏感哈希 + 余弦相似度(model: lsh, similarity: cosine) | ||||
- LSH_L2:局部敏感哈希 + L2距离(model: lsh, similarity: l2) | ||||
- PERMUTATION_LSH:排列局部敏感哈希(model: permutation_lsh) |
查询结果 #
{
"took": 3297,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2,
"hits": [
{
"_index": "my-index",
"_type": "_doc",
"_id": "dewmA5gB0ulPrMzo2K-_",
"_score": 2,
"_source": {
"input_text": "这是另一个示例文本,这次使用 POST。"
}
},
{
"_index": "my-index",
"_type": "_doc",
"_id": "dt2DAZgB6WXmvHRNYksX",
"_score": 1.540483,
"_source": {
"input_text": "这是另一示例文本。"
}
},
{
"_index": "my-index",
"_type": "_doc",
"_id": "bulk_doc_2",
"_score": 1.513369,
"_source": {
"input_text": "第二个批量处理的文本,指定了ID。"
}
},
{
"_index": "my-index",
"_type": "_doc",
"_id": "dd2DAZgB6WXmvHRNYksX",
"_score": 1.4987004,
"_source": {
"input_text": "第一个批量处理的文本。"
}
}
]
}
}
删除搜索管道 #
要删除特定搜索管道,请将管道 ID 作为参数传递:
DELETE /_search/pipeline/<pipeline-id>
要删除集群中的所有搜索管道,请使用通配符 ( * ):
DELETE /_ingest/pipeline/*